
R§«§ŒROC AUC≤Ú¿œ§«ª»§√§ø•«°º•ø•ª•√•»§ÚÕ—§§§∆°¢Python scikit-learn§«µ°≥£≥ÿΩ¨§Ú§‰§√§∆§þ§ÎŒ„°£Jupyter§¨ª»§§§‰§π§§§Œ§«§™§π§π§·°£
»ÛæÔ§ÀÕ≠Ãæ§ •¢•‰•·§Œ•«°º•ø§ŒΩËÕ˝§´§È°£
import sklearn
from sklearn import datasets
from sklearn.datasets import load_iris
iris = datasets.load_iris()
# print(type(iris))
print(iris['DESCR'])
print(iris['data'][0:6,])
print(iris['target'])
# Python 3
# Non-exhaustive cross-validation / Holdout method
import sklearn
from sklearn.linear_model import LogisticRegression,PassiveAggressiveClassifier,RidgeClassifier,SGDClassifier
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier,RandomForestClassifier, BaggingClassifier
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier,ExtraTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.decomposition import TruncatedSVD
from sklearn.model_selection import cross_val_score,train_test_split
iris = datasets.load_iris()
features = iris.data
labels = iris.target
# lsa = TruncatedSVD(3)
# print(lsa)
# reduced_features = lsa.fit_transform(features)
# print(reduced_features.shape)
import pandas as pd
data_frame = pd.DataFrame(index=[], columns=['name','score'])
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=0)
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
# ROC AUC: ValueError: multiclass format is not supported
series = pd.Series([clf_name, score], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
# Multi-layer Perceptron classifier
clf = MLPClassifier(hidden_layer_sizes=(3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
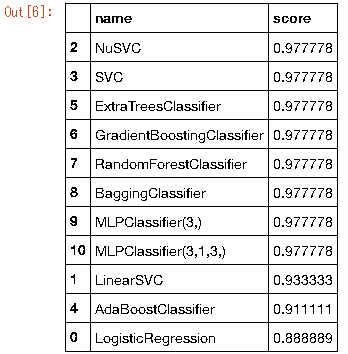
data_frame.sort_values('score',ascending=False)
# Stratified K-Folds cross-validation
# Sturges' formula
import math
k = int(1 + math.log(len(labels))/math.log(2))
skf = sklearn.model_selection.StratifiedKFold(n_splits=k,shuffle=True,random_state=0)
print("Number of folds: ", skf.get_n_splits(features, labels))
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
data_frame = pd.DataFrame(index=[], columns=['name','score'])
count = 0
for train_index, test_index in skf.split(features, labels):
count = count + 1
print("[",count,"]",end="")
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
series = pd.Series([clf_name, score], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
view_frame = pd.DataFrame(index=[], columns=['name','score','score std'])
clf_names.append("MLPClassifier(3,1,3,)")
for clf_name in clf_names :
mean = (data_frame[data_frame['name'] == clf_name]['score'].mean())
std = (data_frame[data_frame['name'] == clf_name]['score'].std())
series = pd.Series([clf_name, mean, std], index=view_frame.columns)
view_frame = view_frame.append(series, ignore_index = True)
view_frame.sort_values('score',ascending=False)
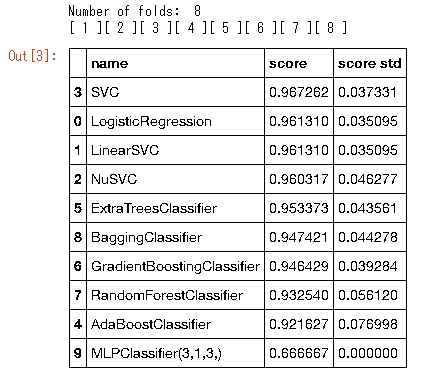
sklearn.model_selection.cross_val_score§Úª»§¶§»•≥°º•…§¨æا §Ø§∆§π§ý°£
# sklearn.model_selection.cross_val_score
# Stratified K-Folds cross-validation
# Sturges' formula
import math
k = int(1 + math.log(len(labels))/math.log(2))
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
data_frame = pd.DataFrame(index=[], columns=['name','score','score std'])
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
scores = sklearn.model_selection.cross_val_score(clf,features,labels,cv=k,verbose=1,n_jobs=-1)
series = pd.Series([clf_name, scores.mean(), scores.std()], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
scores = sklearn.model_selection.cross_val_score(clf,features,labels,cv=k)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", scores.mean(), scores.std()], index=data_frame.columns), ignore_index = True)
data_frame.sort_values('score',ascending=False)
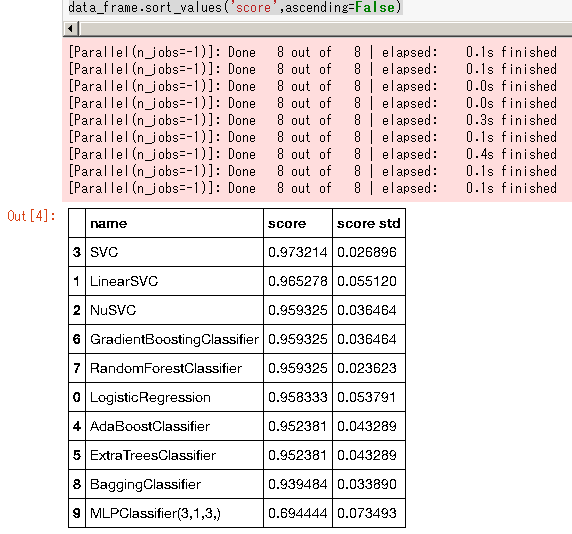
sklearn.model_selection.RepeatedStratifiedKFold§œ0.19∞ 槫•µ•ð°º•»§µ§Ï§ø§Œ§«°¢∏≈§§•–°º•∏•Á•Û§«§œº´¡∞§«•Î°º•◊§Ú≤Û§π…¨Õ◊§¨§¢§Î°£
# sklearn.model_selection.RepeatedStratifiedKFold
# supported in >= scikit-learn 0.19
# Repeated Stratified K-Fold cross validation
print("sklearn.version", sklearn.__version__)
repeat = 5
import math
k = int(1 + math.log(len(labels))/math.log(2))
print("Number of folds: ", k, " Repeat: ", repeat)
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier","PassiveAggressiveClassifier","RidgeClassifier","SGDClassifier",
"GaussianProcessClassifier","KNeighborsClassifier","RadiusNeighborsClassifier",
"DecisionTreeClassifier","ExtraTreeClassifier",]
data_frame = pd.DataFrame(index=[], columns=['name','score'])
for _ in range(repeat) :
skf = sklearn.model_selection.StratifiedKFold(n_splits=k,shuffle=True,random_state=_*100)
count = 0
for train_index, test_index in skf.split(features, labels):
count = count + 1
print("[",_+1,"-",count,"]",end="")
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
series = pd.Series([clf_name, score], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(3,1,3,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
data_frame = data_frame.append(pd.Series(["MLPClassifier(3,1,3,)", clf.score(X_test, y_test)], index=data_frame.columns), ignore_index = True)
view_frame = pd.DataFrame(index=[], columns=['name','score','score std'])
clf_names.append("MLPClassifier(3,1,3,)")
for clf_name in clf_names :
mean = (data_frame[data_frame['name'] == clf_name]['score'].mean())
std = (data_frame[data_frame['name'] == clf_name]['score'].std())
series = pd.Series([clf_name, mean, std], index=view_frame.columns)
view_frame = view_frame.append(series, ignore_index = True)
view_frame.sort_values('score',ascending=False)

matplotlib§«score§Œ•∞•È•’§Ú…¡≤˧π§Î°£
import seaborn
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
X = range(len(view_frame['score'].values))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.barh(X,view_frame.sort_values('score',ascending=True)['score'].values,
xerr=view_frame.sort_values('score',ascending=True)['score std'].values, ecolor='r')
plt.yticks(X, view_frame.sort_values('score',ascending=True)['name'].values)
plt.xlim(0.5, 1.1)
plt.title('Comparisons of Classifiers')
plt.tight_layout()
plt.savefig("scikit-learn0-0.eps")
plt.show()
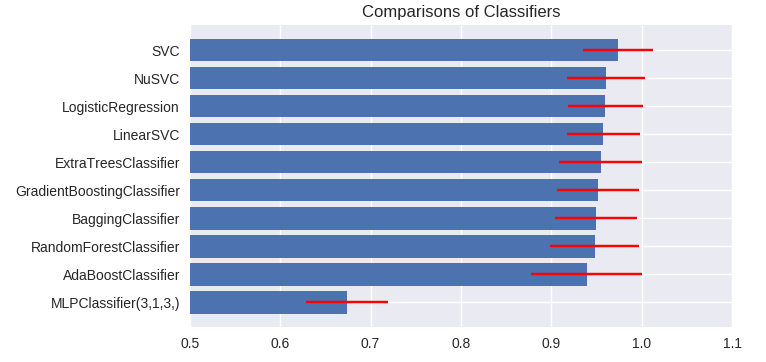
•‚•«•Î¥÷§Œ»Ê≥”§œpairwise t-test§«§‚Œ…§§§Ë§¶§¿§¨°¢•¶•£•Î•≥•Ø•Ω•Û§Œ…‰πÊΩÁ∞Ã∏°ƒÍ(Wilcoxon signed-rank test)§Ú¥´§·§Îœ¿ ∏(Janez Demšar; JMLR:1--30, 2006.)§¨§¢§Î°£
# Statistical Comparisons of Classifiers over Multiple Data Sets
# Janez Demšar; JMLR:1--30, 2006.
# "we recommend a set of simple, yet safe and robust non-parametric tests for statistical comparisons of classifiers:
# the Wilcoxon signed ranks test for comparison of two classifiers and
# the Friedman test with the corresponding post-hoc tests for comparison of more classifiers over multiple data sets"
# http://www.jmlr.org/papers/v7/demsar06a.html
from scipy import stats
t, p = stats.ttest_rel(data_frame[data_frame['name'] == 'SVC']['score'],
data_frame[data_frame['name'] == 'AdaBoostClassifier']['score'])
print( "p = %(p)s" %locals() )
t, p = stats.wilcoxon(data_frame[data_frame['name'] == 'SVC']['score'],
data_frame[data_frame['name'] == 'AdaBoostClassifier']['score'])
print( "p = %(p)s" %locals() )
p = 0.000320439029175
p = 0.000945567746743
KNeighborsClassifier§ÚŒ„§À§»§√§∆°¢≥ÿΩ¨∂ ¿˛§Ú…¡≤˧∑§∆§þ§Î°£/§¿§»æÆøÙ§À§ §Î§Œ§«°¢//§«¿∞øÙ§Ú∆¿°¢np.linspace§«•µ•Û•◊•ÎøÙ§Ú —§®§∆…¡≤˧µ§ª§Î°£
import numpy as np
from sklearn.model_selection import learning_curve
folds = 10
train_sizes, train_scores, valid_scores = learning_curve(KNeighborsClassifier(),
features,labels,cv=folds,
train_sizes=np.linspace(10,len(labels)-len(labels)//folds-1,10,dtype ='int'))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(train_sizes,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(train_sizes,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(train_sizes,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.savefig("scikit-learn8-1.png")
plt.show()
º°§œº´¡∞§Œ•«°º•ø•ª•√•»§Úª»§√§∆§þ§Î°£
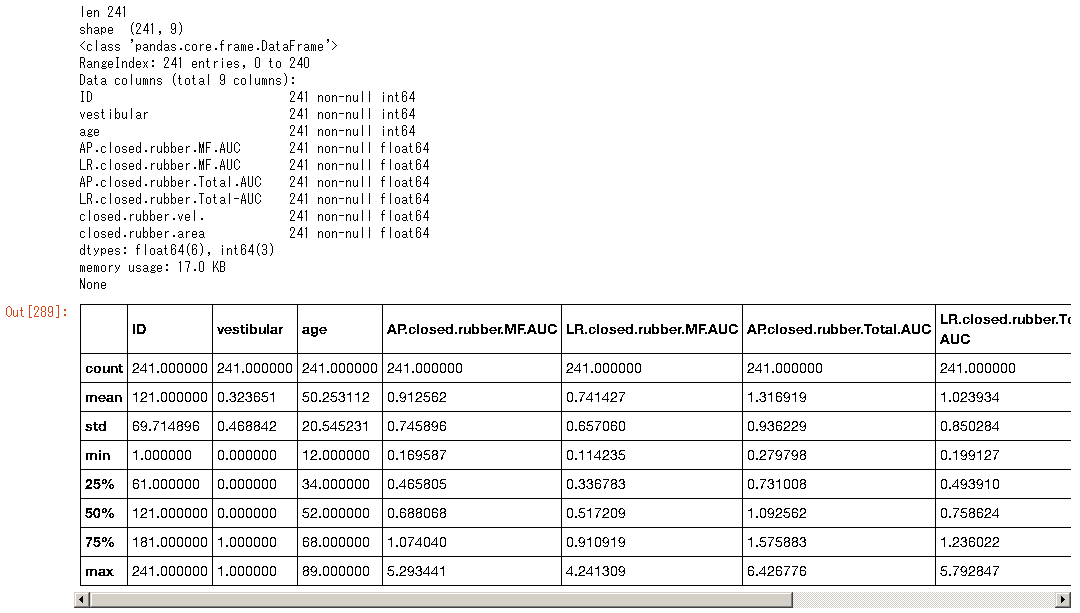
•«°º•ø§œæµ≠R§«§ŒΩËÕ˝§»∆±§∏ ™§Úª»Õ—°£Python pandas§¨ ÿÕ¯°£r3-data.cvs
import pandas as pd
df = pd.read_csv("r3-data.csv")
print("len", len(df))
print("shape ", df.shape)
print(df.info())
df.describe()
#df.head(3)
#df.tail(3)
df.iloc[:2]

¬ø —ŒÃ§ŒæÏπÁ°¢C(Inverse of regularization strength)•—•È•·°º•ø§À§Ë§ÍR§»∆±§∏√Õ§Ú∆¿§Î°£¿µ¬ß≤Ω§∑§ §§æÏπÁ°¢C§À¬Á§≠§ √Õ§Ú∆˛§Ï§Î°£R§«¿µ¬ß≤Ω§π§ÎæÏπÁ§œglmnet§Úª»Õ—§π§Î°£
vest = df.iloc[:,1].as_matrix()
pdat = df.iloc[:,2:].as_matrix()
X = pdat[:,(0,)] # age
y = vest
clf = LogisticRegression(C=1)
clf.fit(X, y)
print( "ROC AUC (C=1) ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]))
X = pdat[:,(1,2,3,4,)] # x2 A-P MF-AUC x3 L-R MF-AUC x4 A-P Total-AUC x5 L-R Total-AUC
y = vest
clf = LogisticRegression(C=1,penalty='l2',solver='liblinear')
clf.fit(X, y)
print( "ROC AUC (C=1) L2 ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]))
clf = LogisticRegression(C=1,penalty='l2',solver='newton-cg')
clf.fit(X, y)
print( "ROC AUC (C=1) L2 ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]))
clf = LogisticRegression(C=10000)
clf.fit(X, y)
print( "ROC AUC (C=10000) ", sklearn.metrics.roc_auc_score(y, clf.predict_proba(X)[:,1]), end="")
print( " <-- without Regularization (= R default output)")
ROC AUC (C=1) 0.558321535315
ROC AUC (C=1) L2 0.871086990719
ROC AUC (C=1) L2 0.869435268208
ROC AUC (C=10000) 0.869592575114 <-- without Regularization (= R default output)
# Non-exhaustive cross-validation / Holdout method
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier
from sklearn.model_selection import cross_val_score
import pandas as pd
features = pdat
labels = vest
data_frame = pd.DataFrame(index=[], columns=['name','score', 'ROC AUC'])
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=0)
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier"]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
if hasattr(clf, 'predict_proba') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])
elif hasattr(clf, 'decision_function') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test))
series = pd.Series([clf_name, score, auc], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
# Multi-layer Perceptron classifier
clf = MLPClassifier(hidden_layer_sizes=(8,8,8,8,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
series = pd.Series(["MLPClassifier(8X4)", clf.score(X_test, y_test), sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])],
index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
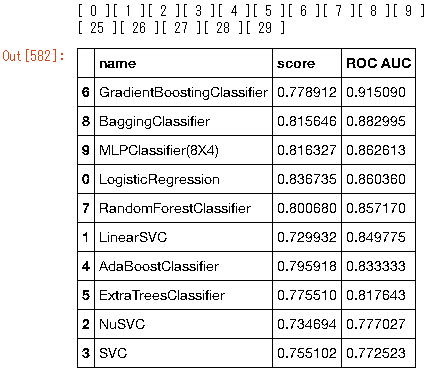
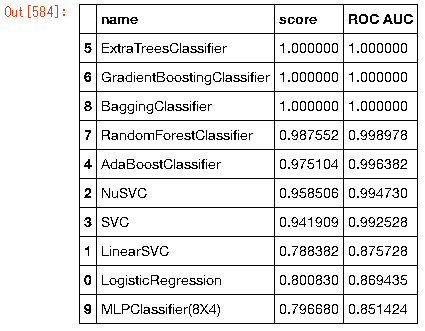
data_frame.sort_values('ROC AUC',ascending=False)
∞Ï»Ã≈™§ ≈˝∑◊§«§Œ¡ý∫Ó§«§œ°¢•«°º•ø•ª•√•»§Ú≥ÿΩ¨•«°º•ø§»•∆•π•»•«°º•ø§À ¨§±§∆ΩËÕ˝§π§Î§≥§»§œ§ §§°£∆±§∏•«°º•ø§«…æ≤¡§∑§øæÏπÁ°¢≤·≥ÿΩ¨§∑§∆∏´§øÃÐæÂŒ…§§√Õ§¨Ω–§Î§≥§»§¨§¢§Î°£
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier
from sklearn.model_selection import cross_val_score
import pandas as pd
features = pdat
labels = vest
X_train = X_test = features
y_train = y_test = labels
data_frame = pd.DataFrame(index=[], columns=['name','score', 'ROC AUC'])
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier","RandomForestClassifier","BaggingClassifier"]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
if hasattr(clf, 'predict_proba') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])
elif hasattr(clf, 'decision_function') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test))
series = pd.Series([clf_name, score, auc], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
# Multi-layer Perceptron classifier
clf = MLPClassifier(hidden_layer_sizes=(8,8,8,8,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
series = pd.Series(["MLPClassifier(8X4)", clf.score(X_test, y_test), sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])],
index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
data_frame.sort_values('ROC AUC',ascending=False)
import sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,NuSVC,SVC
from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier
from sklearn.model_selection import cross_val_score
import pandas as pd
features = pdat
labels = vest
# Repeated Stratified K-Fold cross validation
repeat = 5
import math
k = int(1 + math.log(len(labels))/math.log(2))
print("Number of folds: ", k, " Repeat: ", repeat)
data_frame = pd.DataFrame(index=[], columns=['name','score', 'AUC'])
data_sum = pd.DataFrame(index=[], columns=['name','score', 'AUC'])
clf_names = ["LogisticRegression","LinearSVC","NuSVC","SVC","AdaBoostClassifier","ExtraTreesClassifier","GradientBoostingClassifier",
"RandomForestClassifier","BaggingClassifier"]
for _ in range(repeat) :
skf = sklearn.model_selection.StratifiedKFold(n_splits=k,shuffle=True,random_state=_*100)
count = 0
for train_index, test_index in skf.split(features, labels):
count = count + 1
print("[",_+1,"-",count,"]",end="")
X_train, X_test = features[train_index], features[test_index]
y_train, y_test = labels[train_index], labels[test_index]
for clf_name in clf_names:
clf = eval("%s()" % clf_name)
clf.fit(X_train, y_train)
score = clf.score(X_test,y_test)
if hasattr(clf, 'predict_proba') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])
elif hasattr(clf, 'decision_function') == True:
auc = sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test))
series = pd.Series([clf_name, score, auc], index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
clf = MLPClassifier(hidden_layer_sizes=(8,8,8,8,),activation='tanh',solver="adam",random_state=0,max_iter=10000)
clf.fit(X_train, y_train)
series = pd.Series(["MLPClassifier(8X4)", clf.score(X_test, y_test), sklearn.metrics.roc_auc_score(y_test, clf.predict_proba(X_test)[:,1])],
index=data_frame.columns)
data_frame = data_frame.append(series, ignore_index = True)
view_frame = pd.DataFrame(index=[], columns=['name','score','score std','AUC','AUC std'])
clf_names.append("MLPClassifier(8X4)")
for clf_name in clf_names :
mean = (data_frame[data_frame['name'] == clf_name]['score'].mean())
std = (data_frame[data_frame['name'] == clf_name]['score'].std())
aucm = (data_frame[data_frame['name'] == clf_name]['AUC'].mean())
aucs = (data_frame[data_frame['name'] == clf_name]['AUC'].std())
series = pd.Series([clf_name, mean, std, aucm, aucs], index=view_frame.columns)
view_frame = view_frame.append(series, ignore_index = True)
view_frame.sort_values('AUC',ascending=False)

•®•È°º•–°º§ƒ§≠À¿•∞•È•’§«»Ê≥”§π§ÎøÞ§Ú…¡≤Ë
import seaborn
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
X = range(len(view_frame['AUC'].values))
plt.barh(X,view_frame.sort_values('AUC',ascending=True)['AUC'].values)
plt.yticks(X, view_frame.sort_values('AUC',ascending=True)['name'].values)
plt.errorbar(view_frame.sort_values('AUC',ascending=True)['AUC'].values,X,
xerr=view_frame.sort_values('AUC',ascending=True)['AUC std'].values,
fmt='ro', ecolor='r', capthick=1)
plt.xlim(0.6, 1)
plt.show()
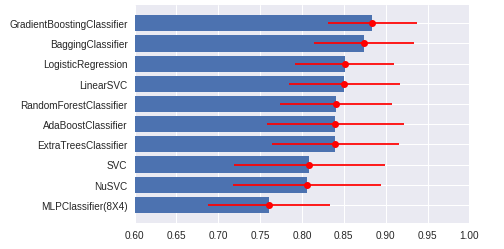
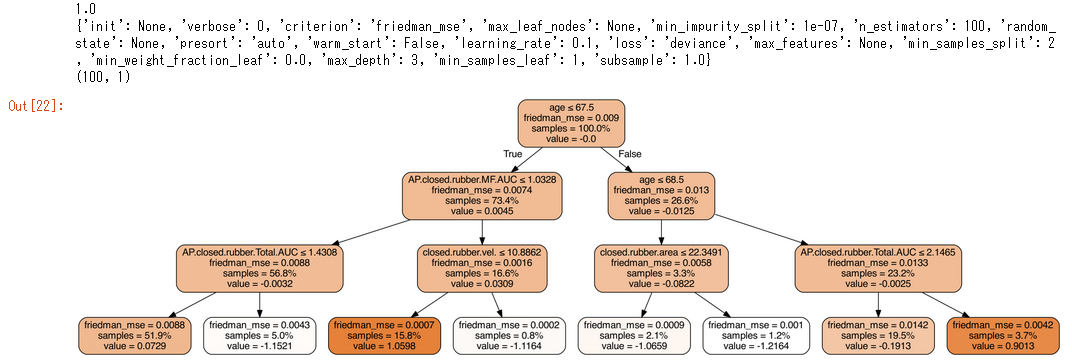
•¢•Û•µ•Û•÷•Î≥ÿΩ¨(Ensemble learning)§«§œ°¢∑˃ÍÃ⁄§¨ £øÙ§¢§Î§Œ§«°¢§π§Ÿ§∆§Ú…Ωº®§∑§∆≥Œ«ß§π§Î§Œ§œ§¢§Þ§Í∞’㧨§¢§Î§≥§»§«§œ§ §§§¨°¢∞Ï…Ù§Ú…Ωº®§∑§∆§™§™§Ë§Ω§Úƒœ§ý§≥§»§¨Ω–Õ˧ΰ£
clf = GradientBoostingClassifier()
clf.fit(X_train, y_train)
print(sklearn.metrics.roc_auc_score(y_test, clf.decision_function(X_test)))
print(clf.get_params())
print(clf.estimators_.shape)
import pydotplus
from IPython.display import Image
sub_tree = clf.estimators_[99,0]
dot_data = sklearn.tree.export_graphviz(sub_tree, out_file=None, filled=True, rounded=True,
special_characters=True, proportion=True,
feature_names=df.columns[2:] )
Image(pydotplus.graph_from_dot_data(dot_data).create_png())
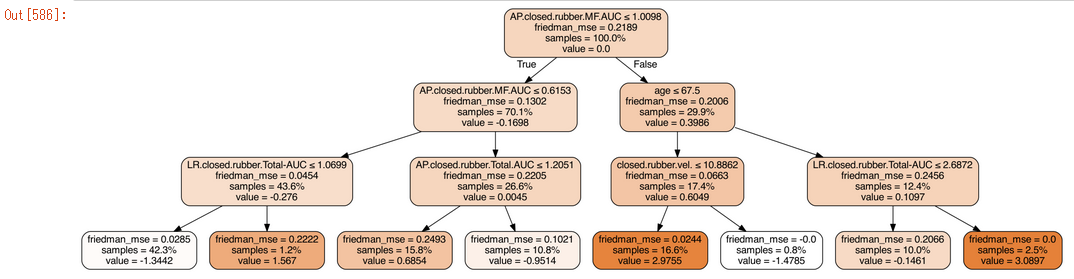
sub_tree = clf.estimators_[0, 0]
dot_data = sklearn.tree.export_graphviz(sub_tree, out_file=None, filled=True, rounded=True,
special_characters=True, proportion=True,
feature_names=df.columns[2:])
Image(pydotplus.graph_from_dot_data(dot_data).create_png())
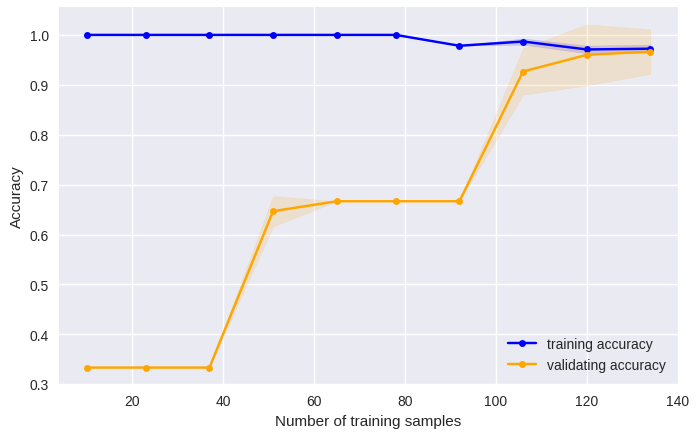
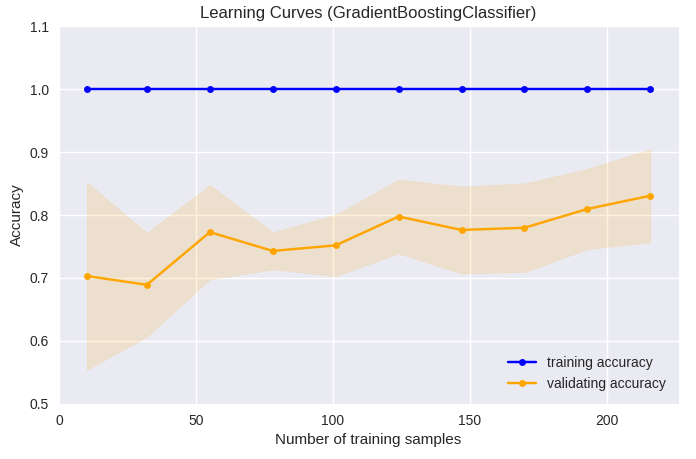
•Ì•∏•π•∆•£•√•Ø≤Ûµ¢§Œ≥ÿΩ¨∂ ¿˛§œ°¢…∏ÀÐøÙ§¨50¡∞∏§«training accuracyµ⁄§”validating accuracy§»§‚§ÀÃÛ0.8§Àº˝¬´§∑°¢ 50∞ 槌…∏ÀÐøÙ§Œƒ…≤√§À§Ë§Î¬Á§≠§ ÕΩ¬¨«Ω§Œ∏˛æ§œ∏´§È§Ï§ §´§√§ø°£Gradient Boosting Clas-sifier§ŒæÏπÁ°¢training accuracy§œ§€§Ð1§«°¢ validating accuracy§œ…∏ÀÐøÙ200§Úƒ∂§®§∆§‚ÕΩ¬¨«Ω§¨∏˛æ§π§Î∑π∏˛§À§¢§Í°¢≤·≥ÿΩ¨§Œ¥Ì∏±¿≠§À√Ì∞’§π§Î…¨Õ◊§¨§¢§Î§¨°¢ …∏ÀÐøÙ§Œƒ…≤√§À§Ë§Í§µ§È§ §ÎÕΩ¬¨«Ω§Œ∏˛æ§¨¥¸¬‘§«§≠°¢•‚•«•Î§ŒÕΩ¬¨«Ω§»§∑§∆§Œ«ΩŒœ§œ•Ì•∏•π•∆•£•√•Ø≤Ûµ¢§Ë§Íπ‚§§§»πÕ§®§È§Ï§ø°£ ∏Ì∫π§Œfill_between§Ú∆©≤·§«EPSΩ–Œœ§π§Î§»¿µæÔ§À…¡≤˧µ§Ï§ §§§≥§»§¨§¢§Î§Œ§«°¢§≥§ŒŒ„§«§œ°¢pngΩ–Œœ§»§∑§∆§§§Î°£
import numpy as np
from sklearn.model_selection import learning_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
train_sizes, train_scores, valid_scores = learning_curve(GradientBoostingClassifier(),
features[indices],labels[indices],cv=folds,
train_sizes=np.linspace(10,len(labels)-len(labels)//folds-1,10,dtype ='int'))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(train_sizes,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(train_sizes,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(train_sizes,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.title('Learning Curves (GradientBoostingClassifier)')
plt.legend(loc='lower right')
plt.ylim([0.5,1.1])
plt.savefig("scikit-learn0-10.png")
plt.show()
import numpy as np
from sklearn.model_selection import learning_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
train_sizes, train_scores, valid_scores = learning_curve(LogisticRegression(),
features[indices],labels[indices],cv=folds,
train_sizes=np.linspace(10,len(labels)-len(labels)//folds-1,10,dtype ='int'))
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(train_sizes,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(train_sizes,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(train_sizes,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(train_sizes,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
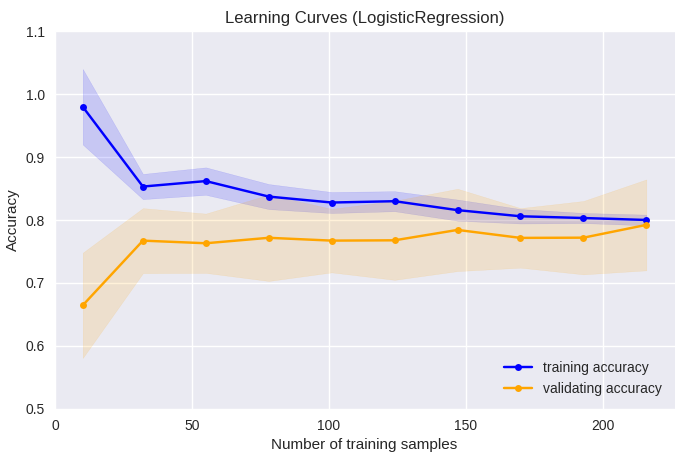
plt.title('Learning Curves (LogisticRegression)')
plt.legend(loc='lower right')
plt.ylim([0.5,1.1])
plt.savefig("scikit-learn0-11.png")
plt.show()
•‚•«•Î§Œ•—•È•·°º•ø§œ°¢§Ω§Ï§æ§Ï§Œ•‚•«•Î§À§™§±§Î¿þƒÍ√Õ§‰¿©∏¬√Õ§«§¢§Í°¢•—•È•·°º•ø§À§Ë§√§∆ÕΩ¬¨¿≠«Ω§œ¬Á§≠§Ø —§Ô§Î§ø§·°¢∫«≈¨§ •—•È•·°º•ø§Œ∑˃ͧœΩ≈Õ◊§«§¢§Î°£ ∫«≈¨§ •—•È•·°º•ø§ÚªªΩ–§π§ÎøÙº∞≈˘§œ¬∏∫þ§ª§∫°¢¥ÀÐ≈™§À°¢∑–∏≥≈™ ˝À°§Þ§ø§œ°¢¡¥§∆§Œ•—•È•·°º•ø§ÀÕÕ°π§ √Õ§Ú≈ˆ§∆§œ§·§∆ÕΩ¬¨¿≠«Ω§ÚªªΩ–§∑∫«¬Á√Õ§Ú√µ§π√µ∫˜≈™ ˝À°§À¥§≈§Ø°£ •Ì•∏•π•∆•£•√•Ø≤Ûµ¢µ⁄§”•¢•Û•µ•Û•÷•Î≥ÿΩ¨§À§™§§§∆°¢§Ω§Ï§æ§Ï§Œ¬Â…Ω≈™§ •—•È•·°º•ø§Œƒ¥¿∞§À§Ë§ÍÕΩ¬¨«Ω§¨§…§Œƒ¯≈Ÿ —≤Ω§π§Î§´…æ≤¡§∑§ø°£
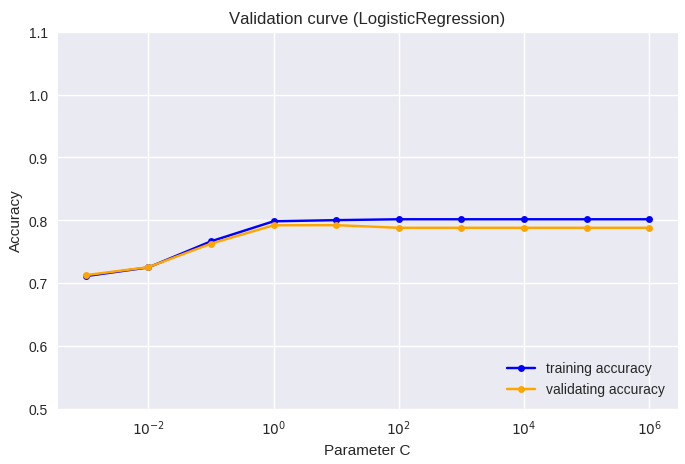
¿µ¬ß≤Ω§œ°¢≤·≥ÿΩ¨§ÚÀ…§∞§ø§·§ŒºÍ√ §«§¢§Í°¢L1¿µ¬ß≤Ω§Þ§ø§œL2¿µ¬ß≤Ω§¨»Ê≥”≈™¬ø§ØÕ—§§§È§Ï§Î°£•◊•Ì•∞•È•ý§Œ¥˚ƒÍ§«§œL2¿µ¬ß≤Ω§¨∫ŒÕ—§µ§Ï§∆§™§Í°¢ §Ω§Œ•—•È•·°º•ø§Œƒ¥¿·§À§Ë§ÍÕΩ¬¨«Ω§¨§…§¶ —≤Ω§π§Î§´§Ú∏°æ⁄∂ ¿˛§À§∆…æ≤¡§∑§ø°£ÀЕ◊•Ì•∞•È•ý§À§™§§§∆§œ°¢C (Inverse of regularization strength)§¨æƧµ§§ª˛§À¿µ¬ß≤Ω§¨∂اذ¢ ¬Á§≠§ ª˛§À§œ¿µ¬ß≤Ω§¨ºÂ§§°£•◊•Ì•∞•È•ý§Œ¥˚ƒÍ§Œ•—•È•·°º•ø§«§¢§ÎC=1§Ë§Í¿µ¬ß≤Ω§Ú∂ااπ§Î§»°¢training accuracyµ⁄§”validating accuracy§»§‚§À∏∫æا∑°¢ ≤·≈Ÿ§ ¿µ¬ß≤Ω§œ•‚•«•Î§ŒÕΩ¬¨«Ω§Ú≤º§≤§Î§»πÕ§®§È§Ï§ø°£
from sklearn.model_selection import validation_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
param_range = np.logspace(-3, 6, num=10)
train_scores, valid_scores = validation_curve(LogisticRegression(),
features[indices],labels[indices],cv=folds,
param_name='C',
param_range=param_range)
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(param_range,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.plot(param_range,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.xscale('log')
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.title('Validation curve (LogisticRegression)')
plt.legend(loc='lower right')
plt.ylim([0.5,1.1])
plt.savefig("scikit-learn0-12.png")
plt.show()
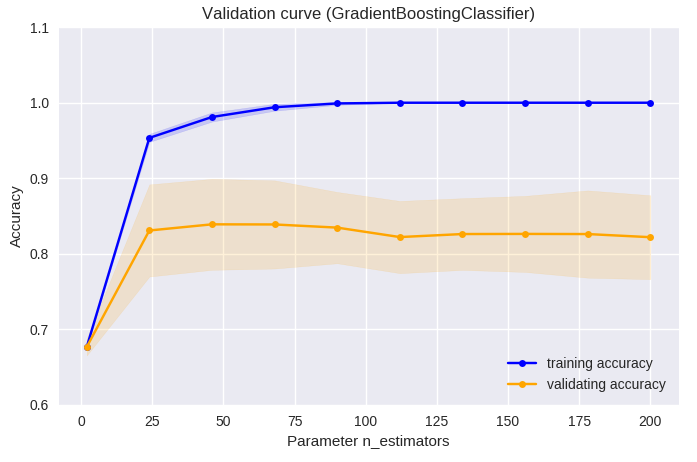
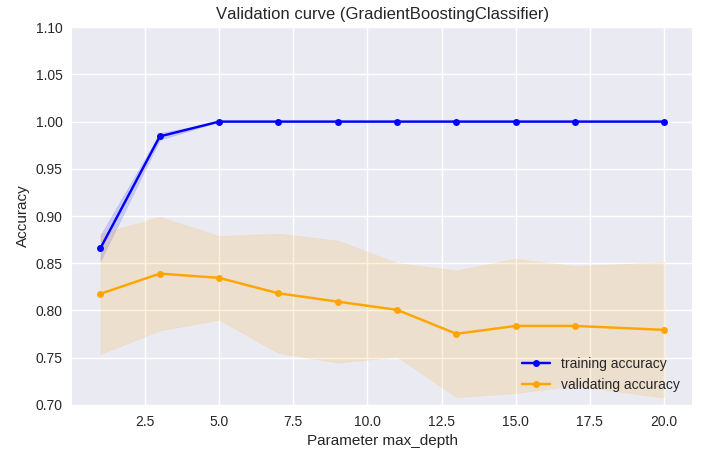
•¢•Û•µ•Û•÷•Î≥ÿΩ¨§œ £øÙ§Œ∑˃ÍÃ⁄§´§È•‚•«•Î§¨∫ӧȧϧࣧ≥§Œ∑˃ÍÃ⁄§ŒøÙµ⁄§”øº§µ§Œƒ¥¿∞§À§Ë§ÍÕΩ¬¨«Ω§¨§…§¶ —≤Ω§π§Î§´∏°æ⁄∂ ¿˛§À§∆…æ≤¡§∑§ø°£ ∑˃ÍÃ⁄§ŒøÙ§À§ƒ§§§∆§œ°¢50¡∞∏§«ÕΩ¬¨«Ω§¨π‚§Ø°¢§Ω§Ï∞ æ¡˝§‰§∑§∆§‚§¢§Þ§ÍÕΩ¬¨«Ω§œ∏˛æ§∑§ §§∑π∏˛§À§¢§√§ø°£∑˃ÍÃ⁄§Œøº§µ§À§ƒ§§§∆§œ°¢ 3¡∞∏§«∫«§‚ÕΩ¬¨«Ω§¨π‚§Ø°¢§Ω§Ï∞ 槌øº§µ§«§œÕΩ¬¨«Ω§¨ƒ„≤º§π§Î∑π∏˛§À§¢§√§ø°£ÀЕ«°º•ø§Œ∫«≈¨•—•È•·°º•ø√µ∫˜§À§™§§§∆§œ°¢øº§µ2°¢ ∑˃ÍÃ⁄øÙ45§Œª˛§À∫«§‚ÕΩ¬¨«Ω§¨π‚§´§√§ø§¨°¢•◊•Ì•∞•È•ý§Œ¥˚ƒÍ§Œ•—•È•·°º•ø§«§¢§Îøº§µ3°¢∑˃ÍÃ⁄øÙ100§Œª˛§ŒÕΩ¬¨«Ω§»Õ≠∞’∫π§œ§ §´§√§ø°£
from sklearn.model_selection import validation_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
param_range = np.linspace(2,200,10,dtype ='int')
train_scores, valid_scores = validation_curve(GradientBoostingClassifier(),
features[indices],labels[indices],cv=folds,
param_name='n_estimators',
param_range=param_range)
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(param_range,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(param_range,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(param_range,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(param_range,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Parameter n_estimators')
plt.ylabel('Accuracy')
plt.title('Validation curve (GradientBoostingClassifier)')
plt.legend(loc='lower right')
plt.ylim([0.6,1.1])
plt.savefig("scikit-learn0-13.png")
plt.show()
from sklearn.model_selection import validation_curve
np.random.seed(0)
indices = np.arange(labels.shape[0])
np.random.shuffle(indices)
folds = 10
param_range = np.linspace(1,20,10,dtype ='int')
train_scores, valid_scores = validation_curve(GradientBoostingClassifier(n_estimators=50),
features[indices],labels[indices],cv=folds,
param_name='max_depth',
param_range=param_range)
plt.figure(num=None, figsize=(8, 5), dpi=100, facecolor='w', edgecolor='k')
plt.plot(param_range,np.mean(train_scores,axis=1), color='blue', marker='o', markersize=5, label='training accuracy')
plt.fill_between(param_range,
np.mean(train_scores,axis=1)+np.std(train_scores,axis=1),np.mean(train_scores,axis=1)-np.std(train_scores,axis=1),
alpha=0.15,color='blue')
plt.plot(param_range,np.mean(valid_scores,axis=1), color='orange', marker='o', markersize=5, label='validating accuracy')
plt.fill_between(param_range,
np.mean(valid_scores,axis=1)+np.std(valid_scores,axis=1),np.mean(valid_scores,axis=1)-np.std(valid_scores,axis=1),
alpha=0.15,color='orange')
plt.xlabel('Parameter max_depth')
plt.ylabel('Accuracy')
plt.title('Validation curve (GradientBoostingClassifier)')
plt.legend(loc='lower right')
plt.ylim([0.7,1.1])
plt.savefig("scikit-learn0-14.png")
plt.show()
I'm not straight - I'm Israeli.
Shlomi Fish (who is not gay)
-- Shlomi Fish
-- Shlomi Fish's Aphorisms Collection ( http://www.shlomifish.org/humour.html )
And the whole problem hinges on the little tiny decision of what IE8 should do
when it encounters a page that claims to support “standards”, but has probably
only been tested against IE7.
What the hell is a standard?
Don’t they have standards in all kinds of engineering endeavors? (Yes.)
Don’t they usually work? (Mmmm…..)
Why are “web standards” so frigging messed up? (It’s not just Microsoft’s
fault. It’s your fault too. And Jon Postel’s (1943-1998). I’ll explain that
later.)
There is no solution. Each solution is terribly wrong. Eric Bangeman at ars
technica writes, “The IE team has to walk a fine line between tight support
for W3C standards and making sure sites coded for earlier versions of IE still
display correctly.” This is incorrect. It’s not a fine line. It’s a line of
negative width. There is no place to walk. They are damned if they do and
damned if they don’t.
-- Joel Spolsky
-- "Martian Headsets" ( http://www.joelonsoftware.com/items/2008/03/17.html )